#AI: NIST проверил DeepSeek V4 на закрытых тестах - отставание 8 месяцев 🔬
👀 DeepSeek V4 Pro выходил с маркетингом "сократили разрыв с американским фронтиром". Американский NIST взял модель на независимое тестирование с закрытыми датасетами - и публичная картина поплыла.
Что нашел CAISI (центр ИИ-стандартов NIST):
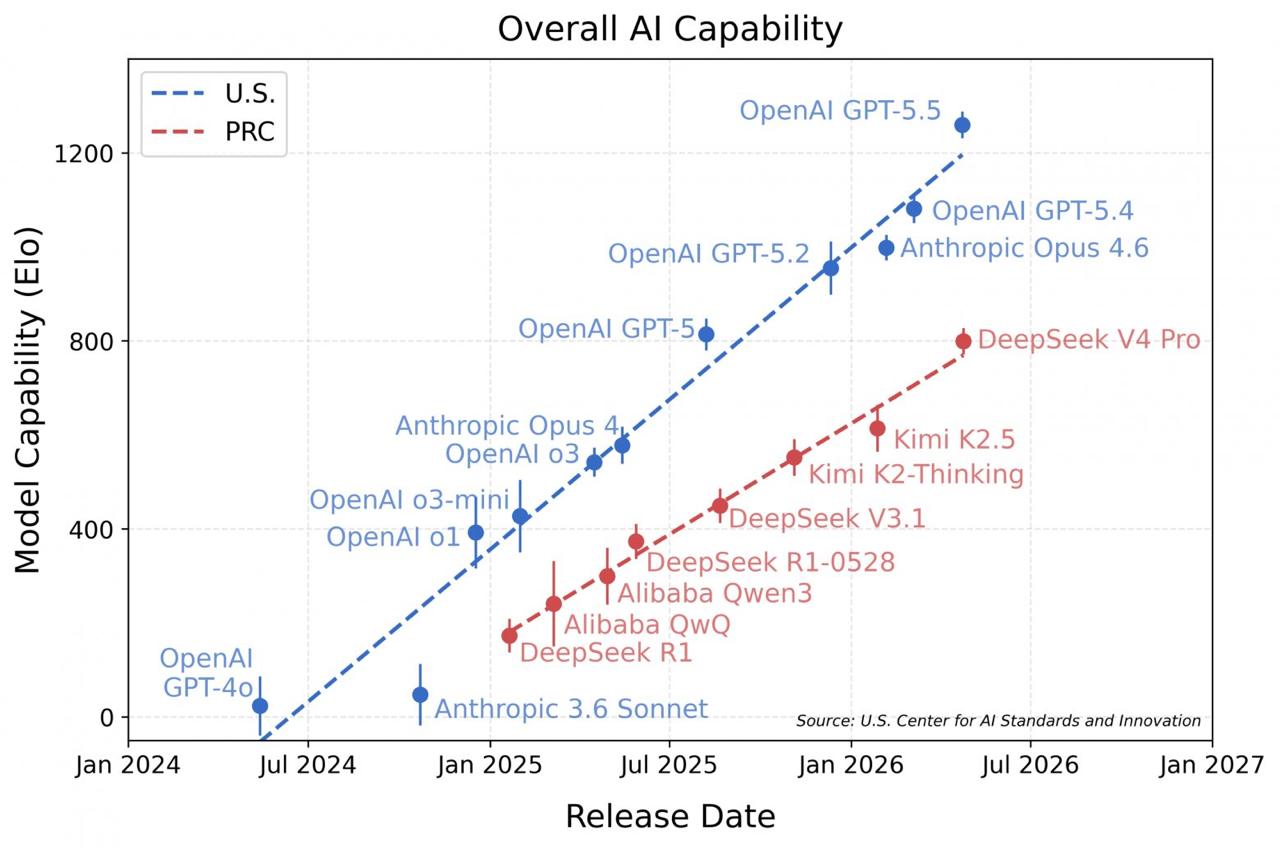
DeepSeek V4 Pro вышел 24 апреля 2026 года. На публичных тестах выглядело убедительно: SWE-Bench Verified - 80,6% против 80,8% у Claude Opus 4.6, почти паритет. Codeforces рейтинг 3 206 - лучший результат среди всех моделей на момент выхода. Bloomberg в тот же день написал что модель "не сократила отставание от американских лидеров" - но это читалось как редакционная позиция. CAISI добавил два датасета которые модель гарантированно не видела во время обучения: ARC-AGI-2 semi-private и собственный PortBench. На них результаты сломались
Закрытые тесты - разрыв в реальности:
🟢 Кибербезопасность (CTF-Archive-Diamond, 285 задач) - V4 Pro: 32% / GPT-5.5: 71%
🟢 Абстрактное мышление (ARC-AGI-2, закрытый датасет) - V4 Pro: 46% / GPT-5.5: 79%
🟢 Инженерия ПО (SWE-Bench Verified) - V4 Pro: 74% / GPT-5.5: 81%
Вывод CAISI однозначный: реальное отставание от американского фронтира - около 8 месяцев, а не 3-6 как в маркетинге DeepSeek. Это устойчивая тенденция с 2025 года - разрыв не сокращается. Хуже всего V4 справляется с длинными сложными задачами: там где нужно удерживать много шагов и контекст одновременно. Именно это отличает реальный агентный workload от синтетики. Механика классическая: компания сама выбирает тесты, берет те где показатели максимальны, получает заголовки "почти догнали" - NIST просто взял задачи которые модель не решала и не обучалась решать
Где DeepSeek V4 выигрывает по делу:
💡 Цена - $0,145 за млн токенов, в 7 раз дешевле GPT-5.5 и Claude Opus 4.7
💡 Открытые веса - можно деплоить локально и дорабатывать под свою задачу
💡 Контекст - 1 млн токенов, архитектура MoE (49 млрд активных из 1,6 трлн параметров)
💡 Генерация кода - рейтинг Codeforces 3 206, рекорд на момент выхода
По цене против возможностей DeepSeek V4 Pro остается одним из лучших вариантов на рынке - особенно для задач где абсолютное качество не критично. Разрыв в 8 месяцев существует, но за 1/7 цены это честный trade-off. Проблема не в модели - проблема в нарративе "почти догнали", который создали вокруг нее
⭐️ Yoshua Bengio, лауреат премии Тьюринга, председатель IASEAI:
"Независимая оценка систем ИИ - не опция, а необходимость. Самооценка компаний не может считаться достаточной для понимания реальных возможностей и рисков моделей"
💭 DeepSeek V4 - сильнейшая открытая китайская модель, и в 7 раз дешевле фронтира. Это реальный аргумент для конкретных задач. Но "сократили разрыв с OpenAI" - это про пресс-релиз, а не про бенчмарк. Восемь месяцев устойчивого отставания на закрытых тестах - это то что видит регулятор, а не маркетинговая команда